선택 정렬
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
선택 정렬은 정렬되지 않은 리스트에서 최솟값(또는 최댓값)을 찾아 정렬된 부분의 끝에 추가하는 방식으로 작동하는 정렬 알고리즘이다. 이 알고리즘은 시간 복잡도가 O(n2)로, 모든 경우에서 동일하며, 배열 내 데이터에 의존하는 루프가 없어 분석하기 어렵지 않다. 선택 정렬은 버블 정렬, 삽입 정렬 등 다른 정렬 알고리즘과 비교되며, 힙 정렬, 이중 선택 정렬, 빙고 정렬과 같은 변형이 존재한다.

더 읽어볼만한 페이지
- 비교 정렬 - 합병 정렬
합병 정렬은 분할 정복 알고리즘을 사용하여 리스트를 재귀적으로 분할하고 정렬된 부분 리스트를 병합하는 비교 기반 정렬 알고리즘으로, O(n log n)의 시간 복잡도를 가지며 안정 정렬에 속하고 연결 리스트 정렬 및 외부 정렬에 유용하다. - 비교 정렬 - 퀵 정렬
퀵 정렬은 토니 호어가 개발한 분할 정복 방식의 효율적인 정렬 알고리즘으로, 피벗을 기준으로 리스트를 분할하여 정렬하는 과정을 재귀적으로 반복하며 다양한 최적화 기법과 변형이 존재한다. - 정렬 알고리즘 - 합병 정렬
합병 정렬은 분할 정복 알고리즘을 사용하여 리스트를 재귀적으로 분할하고 정렬된 부분 리스트를 병합하는 비교 기반 정렬 알고리즘으로, O(n log n)의 시간 복잡도를 가지며 안정 정렬에 속하고 연결 리스트 정렬 및 외부 정렬에 유용하다. - 정렬 알고리즘 - 퀵 정렬
퀵 정렬은 토니 호어가 개발한 분할 정복 방식의 효율적인 정렬 알고리즘으로, 피벗을 기준으로 리스트를 분할하여 정렬하는 과정을 재귀적으로 반복하며 다양한 최적화 기법과 변형이 존재한다.

2. 알고리즘
선택 정렬은 주어진 리스트를 정렬된 부분과 정렬되지 않은 부분으로 나누어, 정렬되지 않은 부분에서 최솟값(또는 최댓값)을 찾아 정렬된 부분의 끝에 추가하는 방식으로 동작한다.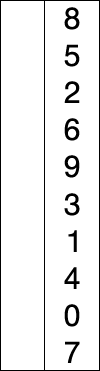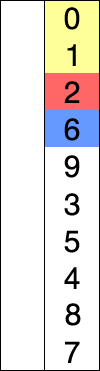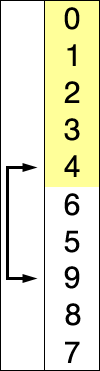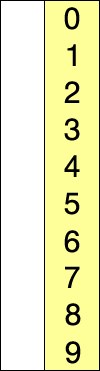
선택 정렬은 연결 리스트와 같은 목록 구조에도 사용할 수 있다.
오름차순 정렬뿐만 아니라 내림차순 정렬도 가능하다. 내림차순 정렬은 최솟값 대신 최댓값을 찾으면 된다.
각 루프마다 최솟값과 최댓값을 모두 찾아 양쪽 끝 요소를 동시에 확정하는 방법을 double selection sort|더블 셀렉션 정렬영어이라고 부른다.
2. 1. 상세 과정
선택 정렬은 다음과 같은 과정을 거쳐 작동한다.1. 주어진 배열에서 최솟값을 찾는다.
2. 찾은 최솟값을 배열의 맨 앞 요소와 교환한다.
3. 정렬된 부분을 제외한 나머지 배열에서 위 과정을 반복한다.
다음은 5개의 요소를 선택 정렬 알고리즘으로 정렬하는 예시이다.
선택 정렬은 연결 리스트와 같은 자료 구조에도 사용할 수 있다. 이 경우, 정렬되지 않은 부분에서 최솟값을 찾아 제거하고, 정렬된 부분의 끝에 삽입하는 방식으로 작동한다.
오름차순 정렬뿐만 아니라 내림차순 정렬도 가능하다. 내림차순 정렬은 최솟값 대신 최댓값을 찾아 정렬하면 된다.
2. 1. 1. 이중 선택 정렬
이중 선택 정렬은 한 번의 탐색에서 최솟값과 최댓값을 모두 찾아 정렬하는 방법으로, 탐색 횟수를 절반으로 줄일 수 있다.[3]선택 정렬의 양방향 변형으로, 각 패스에서 리스트의 최솟값과 최댓값을 ''모두'' 찾는다. 일반 선택 정렬은 항목당 한 번의 비교가 필요하지만, 이중 선택 정렬은 두 항목당 세 번의 비교(요소 쌍 비교, 큰 값을 최댓값과 비교, 작은 값을 최솟값과 비교)가 필요하다. 하지만 패스가 절반으로 줄어들어 순이익이 25% 절감된다.[1]
각 루프마다 최솟값과 최댓값을 모두 찾아 양쪽 끝 요소를 동시에 확정하는 방법을 double selection sort|더블 셀렉션 정렬영어이라고 부르기도 한다.
2. 2. 의사 코드
다음은 선택 정렬의 의사 코드이다.
for i = 0 to n:
a[i]부터 a[n - 1]까지 차례로 비교하여 가장 작은 값이 a[j]에 있다고 하자.
a[i]와 a[j]의 값을 서로 맞바꾼다.
다음은 다른 표현의 의사 코드이다.
for I := 1 to N
min := I
for J := I+1 to N
if data[J] < data[min] then
min := J
end if
end for
swap(data[I], data[min])
end for
3. 예제
다음은 5개의 요소를 선택 정렬로 정렬하는 예시이다.
(마지막 두 숫자가 이미 정렬되어 있었기 때문에 마지막 두 줄에서는 변경된 사항이 없다.)
선택 정렬은 추가 및 제거가 효율적인 연결 리스트와 같은 목록 구조에도 사용할 수 있다. 이 경우, 목록의 나머지 부분에서 최소 요소를 '제거'한 다음, 지금까지 정렬된 값의 끝에 '삽입'하는 것이 더 일반적이다. 예를 들어 다음과 같다.
arr[] = 64 25 12 22 11
// arr[0...4]에서 최소 요소를 찾아서
// 시작 부분에 배치
11 25 12 22 64
// arr[1...4]에서 최소 요소를 찾아서
// arr[1...4]의 시작 부분에 배치
11 12 25 22 64
// arr[2...4]에서 최소 요소를 찾아서
// arr[2...4]의 시작 부분에 배치
11 12 22 25 64
// arr[3...4]에서 최소 요소를 찾아서
// arr[3...4]의 시작 부분에 배치
11 12 22 25 64
4. 복잡도
선택 정렬의 시간 복잡도는 O(n2)이다. 이는 모든 경우(최선, 평균, 최악)에서 동일하다. 구체적인 비교 횟수는 n(n-1)/2이다.
최선, 평균, 최악의 경우일 때 선택 정렬에 소요되는 비교 횟수를 C라고 했을 때, 이를 수식으로 나타내면 다음과 같다.
:
수식에서 N은 테이블(또는 리스트)의 자료 수를 나타내며, Cave는 평균, Cmax는 최대, Cmin는 최소를 나타낸다.
선택 정렬은 배열 내 데이터에 의존하는 루프가 없으므로 다른 정렬 알고리즘에 비해 분석하기 어렵지 않다. 최솟값을 선택하려면 n개의 요소를 스캔해야 하며(n-1번의 비교), 이를 첫 번째 위치로 교환한다. 다음으로 낮은 요소를 찾으려면 나머지 n-1개의 요소를 스캔해야 하며(n-2번의 비교), 이 과정을 반복한다. 따라서 총 비교 횟수는 다음과 같다.
:
등차수열에 의해,
:
이는 비교 횟수 측면에서 O(n2)의 복잡도를 가진다.
정렬할 배열의 요소 수를 n으로 하면, 요소 비교와 관련하여 각 루프에서 n-1회, n-2회, ... 와 같이 수행되며, 전체 처리 횟수는 회이다.
요소 교환과 관련하여 각 루프에서 최대 1회 수행되며, 전체 처리 횟수는 많아야 n-1회이다.
버블 정렬과 비교하면, 요소 비교 횟수는 같지만 교환 횟수가 적기 때문에 선택 정렬이 더 빠르다.
5. 다른 정렬 알고리즘과의 비교
선택 정렬은 버블 정렬이나 그놈 정렬과 같은 다른 2차 정렬 알고리즘보다 성능이 우수하다.[1] 삽입 정렬은 ''k''번째 반복 이후 배열의 처음 ''k''개의 요소가 정렬된 순서로 정렬된다는 점에서 선택 정렬과 유사하지만, 삽입 정렬은 필요한 요소만 스캔하는 반면 선택 정렬은 나머지 모든 요소를 스캔해야 한다는 차이점이 있다.[1]
선택 정렬은 CPU 분기 예측기의 이점을 위해 예측할 수 없는 분기 없이 구현할 수 있다는 장점이 있다. 또한, EEPROM이나 플래시 메모리와 같이 쓰기가 읽기보다 훨씬 비싼 환경에서 쓰기 횟수를 줄일 수 있다. 하지만, 쓰기 횟수는 사이클 정렬이 이론적 최솟값에 더 가깝다.[1]
5. 1. 버블 정렬
버블 정렬은 시간 복잡도가 Θ(''n''2)인 정렬 알고리즘으로, 선택 정렬은 일반적으로 버블 정렬보다 항상 우수하다.[1]5. 2. 삽입 정렬
삽입 정렬은 k번째 반복 이후, 첫 번째 k 요소가 정렬된 순서로 온다는 점에서 선택 정렬과 유사하다.[1] 하지만 선택 정렬은 k+1번째 요소를 찾기 위해 나머지 모든 요소를 탐색하지만, 삽입 정렬은 k+1번째 요소를 배치하는 데 필요한 만큼의 요소만 탐색하기 때문에 훨씬 효율적으로 실행된다는 차이가 있다.[1]간단히 계산해 보면 삽입 정렬은 일반적으로 선택 정렬보다 비교 횟수가 약 절반 정도 적지만, 정렬 전 배열의 순서에 따라 비교 횟수가 같거나 훨씬 적을 수도 있다.[1] 배열의 순서에 관계없이 선택 정렬의 실행 시간은 동일하게 유지되는 반면, 삽입 정렬의 실행 시간은 상당히 달라질 수 있다는 점에서 일부 실시간 컴퓨팅 응용 프로그램에 장점이 될 수 있다.[1] 그러나 배열이 이미 정렬되어 있거나 "거의 정렬된" 경우 삽입 정렬이 훨씬 더 효율적으로 실행된다는 점에서 삽입 정렬에 더 자주 유리하게 작용한다.[1]
선택 정렬은 쓰기 횟수 측면에서 삽입 정렬보다 선호되지만(n-1번의 교환 대 최대 n(n-1)/2번의 교환, 각 교환은 두 번의 쓰기로 구성됨), 이는 최대 n번의 쓰기를 수행하는 사이클 정렬이 달성하는 이론적 최솟값의 대략 두 배이다.[1] 이는 EEPROM 또는 플래시 메모리와 같이 쓰기가 읽기보다 훨씬 비쌀 경우, 모든 쓰기가 메모리의 수명을 단축시키기 때문에 중요할 수 있다.[1]
5. 3. 합병 정렬
선택 정렬은 합병 정렬과 같은 분할 정복 알고리즘을 사용하지만 일반적으로 큰 배열보다 작은 배열(요소 10~20개 미만)에서 더 빠르다.[1] 따라서 충분히 작은 하위 목록에만 삽입 정렬 혹은 선택 정렬을 이용해서 최적화하는 것이 좋다.[1]선택 정렬은 더 큰 배열에서 합병 정렬과 같은 인 분할 정복 알고리즘에 비해 성능이 크게 떨어진다.[1] 그러나 삽입 정렬 또는 선택 정렬은 작은 배열(예: 10~20개 미만의 요소)에 대해 일반적으로 더 빠르다.[1]
6. 안정성
선택 정렬은 안정 정렬이 아니며, 여러 개의 동일한 값을 가진 요소가 있는 배열에 대해 동일한 값의 요소 간 순서는 보존되지 않는다.[1] 예를 들어 배열 (2a 2b 1)에 선택 정렬을 수행하면 다음과 같다. (2a, 2b는 동일한 값으로 한다).
: 2a 2b 1 (초기 상태)
: '''1''' 2b 2a (1번째 루프 종료 시)
: '''1 2b''' 2a (2번째 루프 종료 시)
: '''1 2b 2a''' (종료 상태)
정렬 전후에 2a, 2b의 순서가 변경되어 안정적이지 않음을 확인할 수 있다.[1]
7. 구현
선택 정렬은 다양한 프로그래밍 언어로 구현할 수 있다.
- 자바
```java
void selectionSort(int[] list) {
int indexMin, temp;
for (int i = 0; i < list.length - 1; i++) {
indexMin = i;
for (int j = i + 1; j < list.length; j++) {
if (list[j] < list[indexMin]) {
indexMin = j;
}
}
temp = list[indexMin];
list[indexMin] = list[i];
list[i] = temp;
}
}
```
```cpp
void selectionSort(int *list, const int n)
{
int i, j, indexMin, temp;
for (i = 0; i < n - 1; i++)
{
indexMin = i;
for (j = i + 1; j < n; j++)
{
if (list[j] < list[indexMin])
{
indexMin = j;
}
}
temp = list[indexMin];
list[indexMin] = list[i];
list[i] = temp;
}
}
```
```ocaml
let rec ssort = function
| [] -> []
| h::t -> (ssort (etcList (findMax h t) (h::t))) @ [(findMax h t)]
and findMax a = function
| [] -> a
| h::t -> if a>h then (findMax a t) else (findMax h t)
and etcList a = function
| [] -> []
| h::t -> if h=a then t else h :: (etcList a t);;
```
C 언어와 파이썬 구현 예시는 하위 섹션에서 확인할 수 있다.
7. 1. C
다음은 C 언어로 구현한 예시이다.```c
/* a[0]부터 a[aLength-1]까지 정렬할 배열 */
int i, j;
int aLength; // a의 길이를 초기화
/* 전체 배열을 통해 위치를 이동 */
/* (단일 요소도 최소 요소이므로 i < aLength-1로도 가능) */
for (i = 0; i < aLength - 1; i++) {
/* 정렬되지 않은 a[i .. aLength-1]에서 최소 요소를 찾음 */
/* 최소값이 첫 번째 요소라고 가정 */
int jMin = i;
/* i 이후의 요소와 비교하여 가장 작은 값을 찾음 */
for (j = i + 1; j < aLength; j++) {
/* 이 요소가 더 작으면 새로운 최소값임 */
if (a[j] < a[jMin]) {
/* 새로운 최소값을 찾았으므로 해당 인덱스를 기억 */
jMin = j;
}
}
if (jMin != i) {
swap(&a[i], &a[jMin]);
}
}
7. 2. Python
pythondef selectionSort(x):
length = len(x)
for i in range(length-1):
indexMin = i
for j in range(i+1, length):
if x[indexMin] > x[j]:
indexMin = j
x[i], x[indexMin] = x[indexMin], x[i]
return x
```
파이썬에서의 구현 예를 나타낸다.
제자리 방식의 구현은 다음과 같다.
```python
def minIndex(x, i):
mi = i
for j in range(i + 1, len(x)):
if x[j] < x[mi]:
mi = j
return mi
def swap(x, i, j):
x[i], x[j] = x[j], x[i]
def inplaceSelectionSort(seq):
for i in range(len(seq)):
mi = minIndex(seq, i)
swap(seq, i, mi)
```
비제자리 방식은 위 배열의 복사본을 전달함으로써 실현할 수 있지만, 예를 들어 다음과 같이 직접 구현할 수도 있다.
```python
def nonInplaceSelectionSort(seq):
ind = [*range(len(seq))]
res = []
for i in range(len(seq)):
k = 0
for j in range(len(ind)):
if seq[ind[j]] < seq[ind[k]]:
k = j
res.append(ind.pop(k))
return [seq[i] for i in res]
8. 변형
선택 정렬은 한 번의 탐색에서 최솟값과 최댓값을 같이 찾는 이중 선택 정렬 방식으로 개선될 수 있다. 이 방법은 탐색 횟수를 절반으로 줄여준다. 또한, 한 번 탐색할 때 동일한 값이 있다면 함께 정렬하는 방식으로도 개선할 수 있다. 즉, 최솟값을 찾았는데 그 값과 같은 값이 있다면 다음 탐색 때 최솟값으로 탐색될 것이므로, 미리 정렬하는 것이다. 이 방법은 같은 값이 많을수록 효율적이다.[3]
이중 선택 정렬(칵테일 정렬과 유사하여 칵테일 정렬이라고도 함)은 각 단계에서 리스트의 최솟값과 최댓값을 모두 찾아 탐색 횟수를 줄인다. 이 방법은 항목당 세 번의 비교가 필요하지만, 단계가 절반으로 줄어들어 전체적으로 25%의 성능 향상을 얻을 수 있다.
선택 정렬은 최솟값을 첫 번째 위치에 삽입하고 중간 값을 위로 이동하는 방식으로 안정 정렬로 구현될 수 있다. 그러나 이 방식은 효율적인 삽입이나 삭제를 지원하는 자료 구조가 필요하거나, 쓰기를 수행하게 된다.
8. 1. 힙 정렬
힙 정렬은 "올바른 자료 구조를 사용한 선택 정렬의 구현에 지나지 않는다"라고 묘사된다.[1] 이는 기본적인 알고리즘을 크게 개선하여 암시적 자료 구조인 힙 (자료 구조)를 사용하여 각 최저 요소를 Θ(log n)영어 시간에 찾고 제거한다. 일반적인 선택 정렬의 Θ(n)영어 내부 루프 대신, 총 실행 시간을 Θ(n log n)영어으로 줄인다.8. 2. 빙고 정렬
빙고 정렬은 남은 항목들을 반복적으로 살펴 가장 큰 값을 찾아 그 값을 가진 모든 항목을 최종 위치로 이동하는 방식으로 정렬을 수행한다.[2] 계수 정렬과 같이 중복된 값이 많은 경우에 효율적인 변형이다.[2] 선택 정렬은 이동하는 각 항목마다 남은 항목을 한 번씩 확인하는 반면, 빙고 정렬은 각 값마다 한 번씩 확인한다. 가장 큰 값을 찾기 위한 초기 과정을 거친 후, 다음 값을 찾으면서 해당 값을 가진 모든 항목을 최종 위치로 이동한다.참조
[1]
서적
The Algorithm Design Manual
Springer
[2]
문서
Bingo sort
bingosort
[3]
웹인용
탐색을 응용한 선택 정렬의 개선 방법 제안
https://www.dbpia.co[...]
2021-06
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com